




.png)
Synthetic Data: Democratising Data Access to Improve Patient Outcomes

Presented by: Khaled El Emam, University of Ottawa and Replica Analytics
Edited by: Ben Norris
Synthetic data generation is the process of creating realistic datasets that are not directly associated with real people – the data is based on, and statistically mimics, real datasets. As outlined by Khaled El Emam, from the University of Ottawa and Replica Analytics, machine learning models retain the patterns and statistical properties of real datasets. The anonymity afforded by synthetic data means it can be distributed and used for further analysis with minimal constraint, avoiding complications associated with FAIR data use that can hinder the sharing of data for medical purposes.
Synthetic Data: Medical Deepfakes for Healthcare Advancement
“The basis of synthetic data,” began Khaled El Emam at Oxford Global’s September 2021 Pharma Data and Smartlabs, “is that you start off with a real dataset.” The size of this source dataset can be anything from 50-100 patients to a population in the hundreds of thousands or millions of lives. Generative models capture many of the patterns in the source data, which are subsequently transformed through computer algorithms. “You’ve seen synthetic data before,” said El Emam, likening the technology to the techniques used to create deepfakes – digital likenesses of faces generated from data archives of real people. “The concept of a synthetic dataset works in a similar way, with the difference being that the subject is structured data rather than images.”
“You’ve seen synthetic data before. The concept of structured data works in a similar way to deepfakes.”
One of the benefits of a synthetic dataset is that the purpose of the synthetic data does not need to be known in advance. “Because it’s not personal information, it’s deemed to be non-identifiable or anonymous, which means you can share it with fewer constraints,” continued El Emam. “If you share synthetic data or if you make it available to data consumers, then they’ll be able to perform their analysis and produce similar results with the same conclusions as if they had access to the real datasets.”
Another advantage is that the actual model used to generate synthetic data can be shared in addition to the data itself. “The idea of a simulator exchange is instead of sharing data, you share the models that generate the synthetic data,” El Emam said. “So, you share the generative models, and then you provide access to the data consumers.”
Applications of Synthetic Data and Commitments to Privacy
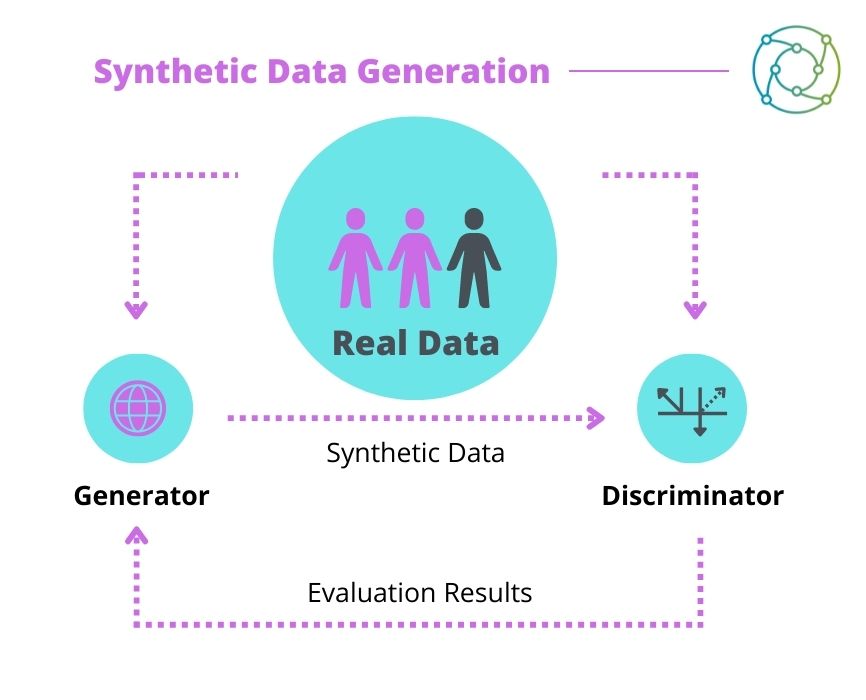
The operation of the generative models used to create synthetic data is logical, as El Emam elaborated. “We essentially have two components – typically a generator and a discriminator” (see Figure 1). The generator produces a synthetic dataset from a real dataset, which the discriminator subsequently analyses and attempts to discern the difference between real and synthetic data. It then produces an evaluation which is sent back to the generator to tune its parameters.
Having established the basic principles of synthetic data, El Emam moved on to discuss privacy. “When we talk about privacy of data, at least in this context, we are talking about identifiability.” He outlined a spectrum of identifiability moving from one to zero, and stressed that data should be as close to the non-identifiable side of the threshold as possible. The threshold number on the spectrum differentiates between personal and non-personal information. He added that “the whole idea of synthesis is that it takes the original data and moves it along the spectrum until it crosses that threshold. Any residual risk is managed through additional controls such as security controls, privacy controls, and contractual controls.”
Overcoming Issues Associated with Traditional Risk Management Approaches
The more traditional risk management model that worked quite well in the past has been facing certain headwinds which has accelerated the adoption of synthetic data generation. “The value of the data diminishes as you apply transformations to it,” explained El Emam. “So what started to happen is organisations applied fewer transformations. And because they only applied a few transformations to preserve the utility of the data, the residual risk was very large, so they ended up having to implement more of these controls.” A negative narrative around traditional de-identification techniques also started to grow around the threat of re-identification attacks by certain bad actors, exposing the identities of patients whose data was supposedly anonymised.
- The Need for a Coordinated Strategy in Digital Data Governance and Healthcare Provision
- Is The Industry Ready for Digital Therapeutics?
- Target Validation: Optimising for Success
El Emam continued that “synthetic data generation attempts to solve that problem.” He explained that the focus shifts to modifying the data to safely parameterise it within an acceptable level of risk. To achieve this, when properly transformed, data identifiability is well below the commonly-used risk threshold of 0.09. This is used by the European Medicines Agency and Health Canada, among others, for creating non-identifiable clinical trial datasets for public release.
“The probability of reunification of synthetic data with the patients it is derived from is quite low,” continued El Emam, “well below the 0.9 threshold.” Protecting the data in this way ensures that privacy can be maintained without compromising data utility. “The risks are significantly below the threshold even without any additional controls,” he added. “If you add controls then the risk will decrease further.”
Further Applications of Synthetic Data
Further to the benefits outlined above, real-world data diversity can be increased by augmenting datasets with virtual models (see Figure 2). “You use patients that have been recruited after a certain point in the trial, build the generative model from these patients and simulate the remaining patients,” continued El Emam. “We’re finding that by using generative models, we are able to draw the same conclusions from these hybrid controls compared to the real patient controls.” This can be helpful for assisting patients with rare diseases, as datasets for these are typically small.
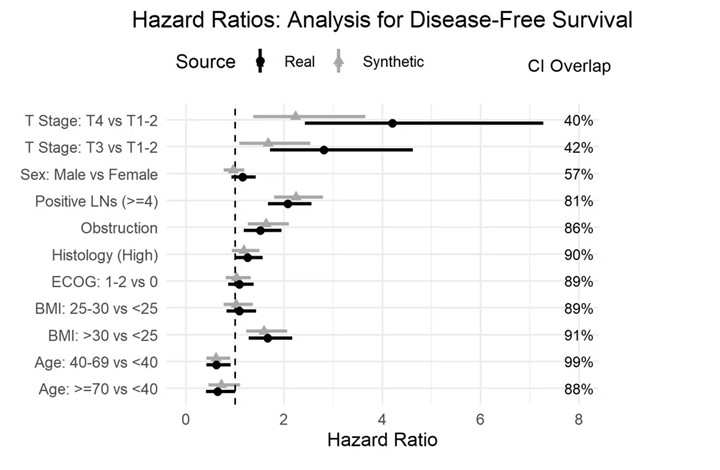
Finally, synthetic patients can be used in prognostic or generative models to accurately simulate outcomes. “Because synthetic data generation models are essentially simulators, they can play the role of quite sophisticated prognostic models,” El Emam added. These models can be powerful tools, and can be used to run personalised simulations for individual patients based on their initial values.
Overcoming problems surrounding privacy and having the ability to share data with minimal constraints is one of the more powerful applications of synthetic data generation. El Emam concluded that there is plenty to keenly anticipate in the field of synthetic data. “As of today, the ability to share data with minimal constraints and meet all of the privacy obligations is one of the more powerful applications of synthetic data generation.”
Visit our PharmaTec portal to read more articles about the latest advances in Digital Medicine, including new discussions around data flow and regulatory approval. If you’d like to register your interest in our upcoming Pharma Data UK: In-Person event, click here.
Related Resources

